Solving Cribbage Solitaire
A few days ago, I read on the Unofficial Zachtronics discord server about someone finding the best score for all deals in Cribbage Solitaire from Möbius Front ‘83 (also available in The Zachtronics Solitaire Collection). There was also a link to a video of someone else explaining their own solver. My curiosity was piqued and I wanted to make my own. I saved both links for future reference. The added benefits of not being the first is that I can validate my results and compare against what’s been done, hopefully learning something in the process. I’ll detail the process I went through to write the program and what I gained from it.
Cribbage Solitaire
Cribbage Solitaire is played with a standard 52 card deck. They’re dealt in 4 columns like so.


Theorycraft
Remembering lessons from my Sudoku Solver, I considered brute force first. It’s the simplest way to ensure correctness.
I had a suspicion the search space would be massive and while I didn’t watch Jonathan Paulson’s video, I did see the title… So my first thoughts went to Dynamic Programming, which is basically a brute force method combining recursion and memoization. I’ve used it in several Advent of Code puzzles over the years. I usually associate dynamic programming with Depth First Search (DFS) to better leverage memoization. I’m not 100% sure about that last point, but intuitively it makes sense to me.
So the plan was: go down the tree of possible moves using Depth-First Search and save the results. If we encounter a game state we’ve already seen, we can use the previously computed scores.
How big is the search state? A very naive upper bound is that we can chose from 4 columns 52 times in a row. 4**52 = 2e+31, so we need to be smarter than that. (I know it’s actually (4**49)*3*2*1, it doesn’t matter).
What do we really need to know about a game state? We need to know how many cards are left in each column. We also need to know the current overall score and the current stack score. To accurately compute said stack score we need to know about the cards played on that stack. The maximum number of cards in a stack is 13 (1*4 + 2*4 + 3*4 + 4 = 28, with the next lowest card bringing the stack total above 31). However, keeping track of 13 cards is superfluous. The highest straight is 7 cards long (1 + 2 + 3 + 4 + 5 + 6 + 7 = 28), so you only need to keep track of the last 6 cards.
struct State
{
int cardsDrawn[4]; // 14**4
int stackScore; // 32
int stack[6]; // 4**6
int score; // Only relevant to discard inferior game states
};
Where does the 4**6 come from? We only need to know what column we drew from. The card value doesn’t matter for differentiating game states, and 4**6 is much lower than 13**6. So we have 14**4 * 32 * 4**6 = 5e+9 game states. That’s… manageable.
But we can’t store the state as is in our cache. It’s 48 bytes, which would mean a 250 GB array.
What we really want to know is the best score a state will lead to, so we only need to store the score in our hash map. The remaining information can be used to compute the hash. How big can the score really be?
Interlude: Score upper bound
We’re not looking for a 100% accurate value here, only how little bits we can realistically use to store a score.
The highest score density per card is getting four of a kind, which nets 20 points for 4 cards. If we could get that for all faces, that’d be 20 * 13 = 260 points, so 8 bits looks doable.
You can get four of a kind up to face card 7, so that’s 140 points. At this point you won’t get in more than 3 cards in each stack for straights, so triples are the next highest scoring stacks. You can get 6 (8, 9, 10, J, Q, K) for a total of 48 points. At this point you have 6 cards left and you can get 2 straights for 6 points.
Add 2 initial jacks (4 points) and maybe a couple of 2 pointers for hitting a stack sum of 15 while doing the squares.
We have an upper bound around 200 (140 + 48 + 6 + 4 + 2*(2? 3?)).
The score will definitely fit into 8 bits and definitely won’t fit in 7 (even if it did, I don’t think the trade-off would be worth it).
Back to planning
So we can store our hashmap in about 5GB. Which, again, is manageable and probably good enough for a proof of concept solver.
But it’s not ideal. Is there any way we can reduce it? As I wrote in the comment next to the score member in the struct, it’s only relevant to discard inferior game states.
At this point I realized I’d started slightly wrong. This is a search problem with a cost function. It’s textbook Dijkstra.
While taking notes, I wrote the following sentence:
A regular DFS constrains us to a successor function between states that simply picks one of the 4 possible columns. If we’re considering Djikstra, maybe we can use a more complex function and reduce the search space.
That’s not actually true. You can design whatever successor function you want even for your DFS. I simply associated DFS with a simple parent/child relationship, and Dijkstra with something more complex. It’s great when I figure out why I was approaching something wrong. I usually gain a deeper understanding of both myself and the topic at hand.
Anywho, if we define a state as the remaining cards in between stacks, we can use a successor function to try all possible stacks for a given state. In that case, we only care about how many cards remain in each column and the score. As I said previously, any non-maximum score for a given state is irrelevant. So now we only have 14**4 = 38416 states!
Trying all possible stacks is work we have to do anyway, so we might as well reduce the memory footprint by a factor of 1e+5… It seemed slightly harder to implement, but at this point I couldn’t justify going for the initial approach. 38K comfortably fits into the CPU cache, probably even in L2 of most modern CPUs.
Given this, it’s pretty easy to have a simple hash function that guarantees no collisions.
struct State {
int cardsDrawn[4] = {}; // 14**4
int GetHash() {
int result = 0;
for ( int i = 3; i >= 0; --i ) {
result *= 14; // Base 14
result += cardsDrawn[i];
// Alternatively, pack every 4 bits
// result <<= 4;
// result |= cardsDrawn[i];
}
return result;
}
};
I chose base 14. It’s a smaller cache and I don’t expect to unhash. This would be the main drawback, using division and modulo is slow.
Now we’re coding
So I set to work on a first working implementation, using whatever came to mind. After some debugging, I managed to get a program that output a credible maximum score. But there was an issue…
Interlude: The difference between finding the best score and knowing how to achieve it.
I’m used to implementing Djikstra in Advent Of Code where the only thing that matters is usually the result, not how you get there. I wanted to check in game that my program followed the game rules, but hadn’t implemented a way to retrieve the steps!
There are a few ways to solve this, I chose to save a link to the state’s parent and a list of moves that led to that state from the parent. This required additions to the GameState data structure and storing all of a state’s data rather than just the score achieved. But since I only had 38K of those rather than 5 billions, it really didn’t matter. A couple of MBs isn’t 200GB.
struct GameState {
u16 parent = UINT16_MAX; // Used to retrace the path and print the solution
MoveList moveList = {};
u8 moves = 0;
u8 cardsDrawn[s_numColumns] = {};
u8 score = 0;
u8 sum = 0;
bool inQueue = false; // SPOILER ALERT
}
Deal #0030
Best Score: 109
Min Time: 27.9185 s
Max running state stack length: 116
States pushed to stack: 412542
States culled: 500'389'624
Playstack call counter: 1'057'318'246
Moves: 222_223_11233_134_42231_234_1424_124_11231414_233334_4413144_13
This seemed very slow… Instinctively, it also seemed like way, way too many pushes to stack. But first, I needed to check that the score was correct. No sense optimizing an incorrect algorithm.
Note: All times will be on the same Deal, which was the next one in my game and just happened to be a long one. I usually ran it about 10 times in a row and took the minimum.
Checking correctness
I went and grabbbed Jonathan Paulson’s solution. I didn’t look at the code, but simply ran his program on the same deal. On my machine, his took about 40 seconds and the memory used by the program was 10 GB. This seemed to match with the approach I initially discarded. (Indeed, I checked the code afterwards and it uses a 14**4 * 32 * 4**6 array of shorts for the cache). But most importantly, it showed I had the correct score.
However, I wasn’t satisfied with the time. I checked DevilSquirrel’s repo (and learned about the existence of the Beef programming language). The score matched, but their solution took around 2 seconds.
Back to the drawing board
There really isn’t much to compute here, a 10x or so difference suggests an algorithmic flaw.
I realized I’d stuck to DFS from my initial idea and trying to minimize the memory footprint. But DFS really doesn’t work well for Dijkstra. So I switched to BFS.
This is a trivial operation, simply use a queue instead of a stack. The only difference is the Pop function. Since I knew the maximum size in advance, I could just use the simple version shown below. No runtime allocations.
struct Queue {
u16 hashes[g_cacheSize] = {};
int first = 0;
int last = 0;
int max = 0;
int pushCount = 0;
void PushBack(u16 hash) {
++pushCount;
assert(last < g_cacheSize);
hashes[last++] = hash;
max = last > max ? last : max;
}
u16 PopFront() {
assert(first < last);
return hashes[first++];
}
bool Find(u16 hash) {
for (int i = first; i < last; ++i) {
if (hashes[i] == hash) {
return true;
}
}
return false;
}
};
Deal #0030
Best Score: 109
Min Time: 2.46625s, was 27.9185s
Max running state queue length: 9029, was 116
States pushed to queue: 34250, was 412542
States culled: 40'359'029, was 500'389'624
Playstack call counter: 84'846'792, was 1'057'318'246
Now that’s more like it! As expected, the memory footprint (Max running state queue length) of DFS is much smaller, or rather it would be if I didn’t allocate the maximum theoretical size upfront. But it’s also much slower because there’s a lot of duplicated work on problems like this one.
I initially used a recursive Playstack function to… well, simulate playing a stack of cards. Recursion was easy to set up and allowed automatic “cleaning” of paths after use. Like a garbage collector, if you will (hint hint). The counter shows I called that function over 1 billion times with the DFS approach versus under 100 million times for BFS.
The Playstack function has mostly logic and little actual computations.
Click here to see code snippet (very optional)
void PlayStack( CardStack& cardStack, Deal & deal, Queue& searchQueue) {
bool hasDrawn = false;
for (u8 i = 0; i < 4; ++i) {
const u8& cardsDrawn = cardStack.state.cardsDrawn[i];
if (cardsDrawn == 13) {
continue;
}
const u8 card = deal.columns[i].cards[cardsDrawn];
const u8 rank = card < 11 ? card : 10;
u8 newSum = cardStack.sum + rank;
if (newSum > 31) {
continue;
}
hasDrawn = true;
CardStack newCardStack = cardStack;
++newCardStack.state.cardsDrawn[i];
newCardStack.sum = newSum;
newCardStack.state.moveList[newCardStack.state.moves++] = i+1;
u8& newScore = newCardStack.state.score;
if (card == 11 && newCardStack.currentCardIndex == 0 ) { // Initial jack
newScore += 2;
}
if (newSum == 31 || newSum == 15) {
newScore += 2;
}
s8 & currentIndex = newCardStack.currentCardIndex;
newCardStack.cards[currentIndex] = card;
assert(currentIndex < 13);
if (currentIndex > 0) {
// Detect sets using the new card
u8 setIncrementIndex = 0;
for (int i = currentIndex-1; i > -1; --i) {
if (newCardStack.cards[i] != card) {
break;
}
setIncrementIndex++;
}
// setIncrement == [0, 2, 6, 12];
newCardStack.state.score += setIncrement[setIncrementIndex];
// Detect straights using the new card
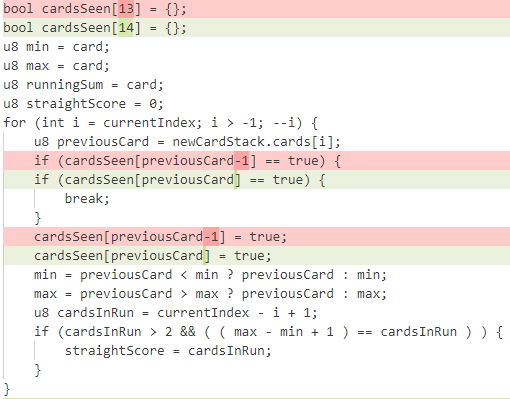
bool cardsSeen[13] = {};
u8 min = card;
u8 max = card;
u8 runningSum = card;
u8 straightScore = 0;
for (int i = currentIndex; i > -1; --i) {
u8 previousCard = newCardStack.cards[i];
if (cardsSeen[previousCard-1] == true) {
break;
}
cardsSeen[previousCard-1] = true;
min = previousCard < min ? previousCard : min;
max = previousCard > max ? previousCard : max;
u8 cardsInRun = currentIndex - i + 1;
if (cardsInRun > 2 && ( ( max - min + 1 ) == cardsInRun ) ) {
straightScore = cardsInRun;
}
}
assert(straightScore < 8);
newCardStack.state.score += straightScore;
}
currentIndex++;
PlayStack(newCardStack, deal, searchQueue);
}
if (!hasDrawn) {
u16 stateIndex = cardStack.state.GetHash();
GameState& currentBest = cache[stateIndex];
if (cardStack.state.score > currentBest.score) {
currentBest = cardStack.state;
if (searchQueue.Find(stateIndex) == false) {
searchQueue.Push(stateIndex);
}
if (currentBest.score > bestScore) {
bestScore = currentBest.score;
bestScoreIndex = stateIndex;
}
}
}
}
More targeted profiling is useless in this case. Each call to Playstack is shorter than 1µs and attempting to measure specific parts introduces way too much noise. Below is an illustration where I attempted a more detailed profile. It resulted in a 6x slowdown.
Best Score: 109
Min Time: 14.9304 s
Time spent copying stacks: 1.65355 s
Time spent checking stack values: 1.61674 s
Time spent checking sets: 1.65461 s
Time spent checking straights: 1.98063 s
Moves: 222_223_11233_134_42231_234_1424_124_11231414_233334_4413144_13
Algorithmic improvements
Remember bool inQueue = false; // SPOILER ALERT from the GameState structure? What’s with the spoiler alert?
DevilSquirrel’s solution was still about 1.25x faster than mine. The next thing I looked at was my queue. A fundamental part of pathfinding algorithms is that you don’t want to visit the same vertex twice. This usually requires checking to see if an item is in your queue, and why I had a find function.
bool Find(u16 hash) {
for (int i = first; i < last; ++i) {
if (hashes[i] == hash) {
return true;
}
}
return false;
}
This wasn’t much of a problem when I was using DFS and the maximum stack size was 116. With BFS and a maximum queue length of 9K, that’s another story. I was iterating through a total of 705'674'814 queue items now in my find function.
Max running state queue length: 9029
Queue Find counter: 114148
Iterations in queue find: 705'674'814
The usual way to solve this issue is to have a hashmap of <item, bool> indicating whether an item is in it. Having realized I needed to print the solution, I already had such a cache of GameState. So I added the boolean and got rid of the find function.
Min Time: 1.72666s, was 2.46625s
My next goal was to get rid of the recursion, as I suspected it brought significant overhead. This meant keeping a scratch GameState and undoing moves every once in a while. There isn’t much to undo, so I was fairly confident it’d still end up faster. But before that, having beat DevilSquirrel’s time, I’d earned the right to peek at their code. It used the same high-level strategy, and indeed had a non-recursive handling for their version of Playstack.
It was well done, too. I couldn’t find significantly better or simpler, so I used mostly the same thing. And indeed, it was faster than the recursive version.
Min Time: 1.59316s, was 1.72666s
Interlude: sometimes less is more (but not in a good way!)
A common strategy for optimizing pathfinding problems is to find ways to discard states so that you don’t consider their children. It’s not easy for this game, where the last 4 cards can get you up to a fourth of the total score, but you can use that info to ensure you don’t discard too much. I attempted this filter to skip states where it was impossible to beat the best score even while getting all four of a kinds:
bool CanBeatBest() {
int factor = 1 + (cardsLeft >> 2);
return (g_bestScore - score) <= (20 * factor);
}
Using it before inserting a state in the queue performed the same as not using it. It only prevented about 50K calls to ComputeScore (out of 84 millions) but didn’t offset the cost in extra instructions for the test (and probably branch misses).
Using it before drawing a card in the PlayStack function prevented 2 million calls to ComputeScore but was 1.22x slower. I couldn’t find a better filter.
Code improvements
I’d run out of architectural/algorithmic improvements. With so little computation and data movement, I didn’t see any hope for SIMD. From my understanding, multithreading Dijkstra is usually impossible. I started looking at the details of the hot loops with some superficial assembly investigation. My attention was brought to something in my function for computing the score of a stack.
void ComputeScore() {
int& currentIndex = moves;
int& moveScore = moveList.scores[currentIndex]; // MISTAKE HERE
int card = moveList.cards[currentIndex];
if (card == 11 && currentIndex == 0) { // Initial jack
moveScore += 2;
}
if (sum == 31 || sum == 15) {
moveScore += 2;
}
if (currentIndex > 0) {
// Detect sets using the new card
int setScore = 0;
for (int i = currentIndex - 1; i > -1; --i) {
if (moveList.cards[i] != card) {
break;
}
setScore += 2;
moveScore += setScore;
}
// Detect straights using the new card
bool cardsSeen[14] = {};
int min = card;
int max = card;
int straightScore = 0;
cardsSeen[card] = true;
for (int i = currentIndex - 1; i > -1; --i) {
int previousCard = moveList.cards[i];
if (cardsSeen[previousCard] == true) {
break;
}
cardsSeen[previousCard] = true;
min = previousCard < min ? previousCard : min;
max = previousCard > max ? previousCard : max;
int cardsInRun = currentIndex - i + 1;
if (cardsInRun > 2 && ((max - min + 1) == cardsInRun)) {
straightScore = cardsInRun;
}
}
assert(straightScore < 8);
moveScore += straightScore;
}
score += moveScore;
}
It’s subtle, but taking a reference for the variable moveScore is a mistake here. I don’t care about the initial value, it will be 0. More importantly, every add is to memory. (Following asm edited for clarity)
lea r9,[rbx+0000000000000084h]
lea r9,[r9+rcx*4] ;Compute moveScore's address
cmp edx,0Bh ; if ( card == 11 ...
jne 00007FF729E110C9
test ecx,ecx ; ... && currentIndex == 0 )
jne 00007FF729E110C9
add dword ptr [r9],2 ;moveScore += 2;
mov eax,dword ptr [rbx+14h]
sub ecx,0Fh ; sum == 15
test ecx,0FFFFFFEFh ; sum == 31 (31 - 15 is 0x10, clever stuff)
jne 00007FF729E110DA
add dword ptr [r9],2 ;moveScore += 2;
mov ecx,dword ptr [rbx+18h]
mov eax,dword ptr [r9]
mov r8d,eax ;Move value to R8, possibly to avoid several memory adds in the setScore loop
; Removed 17 instructions computing setScore
add r8d,r10d ;moveScore += setScore;
sub rax,4
mov dword ptr [r9],r8d ;Move back to memory
; Removed 36 instructions computing straightScore
add dword ptr [r9],edi ;moveScore += straightScore;
mov eax,dword ptr [r9]
mov rdi,qword ptr [rsp+40h]
mov rsi,qword ptr [rsp+38h]
add dword ptr [rbx+10h],eax ;score += moveScore;
Initializing moveScore on the stack and copying to the GameState at the end of the function not only reduced the number of memory operations, it also let the compiler inline the ComputeScore function (I’m not sure why). The resulting assembly is harder to follow as a result, with instruction reordering and whatnot, but it’s better.
cmp eax,0Bh ; if ( card == 11 ...
jne PlayStack+13Fh (07FF763EA11CFh)
test edx,edx ; ... && currentIndex == 0 )
cmove r8d,ebx ; Initialize moveScore to 2 (else it stays at 0)
mov ecx,dword ptr [r10+14h]
sub ecx,0Fh ; sum == 15
test ecx,0FFFFFFEFh ; sum == 31 (31 - 15 is 0x10, clever stuff)
jne PlayStack+152h (07FF763EA11E2h)
add r8d,2 ; moveScore += 2;
test edx,edx ;07FF7053811E2h
jle PlayStack+20Ah (07FF763EA129Ah)
lea ecx,[rdx-1]
mov r9d,esi
movsxd rdx,ecx
mov rdi,rdx
cmp rdx,0FFFFFFFFFFFFFFFFh
jle PlayStack+18Ch (07FF763EA121Ch)
lea rcx,[r10+50h]
lea rcx,[rcx+rdx*4]
cmp dword ptr [rcx],eax ; 07FF705381204h
jne PlayStack+18Ch (07FF763EA121Ch)
add r9d,2 ; setScore += 2
dec rdx
add r8d,r9d ; moveScore += setScore
sub rcx,4
cmp rdx,0FFFFFFFFFFFFFFFFh
jg PlayStack+174h (07FF705381204h)
; Removed 28 instructions pertaining to straightScore and what follows in the PlayStack function, since ComputeScore was inlined.
cmove ebx, edx ; straightScore = cardsInRun
inc edx
dec rdi
sub rsi, 4
cmp rdi, 0FFFFFFFFFFFFFFFFh
jg PlayStack + 1C0h(07FF763EA1250h)
xor esi, esi
add r8d, ebx ; moveScore += straightScore
mov ebx, 2
lea edi, [rbx + 8]
mov dword ptr[r10 + rbp * 4 + 84h], r8d ; moveList.scores[currentIndex] = moveScore
mov edx, esi
add dword ptr [r10+10h],r8d ; score += moveScore
Min Time: 1.44067s, was 1.59316s
1.1x faster with this simple change isn’t bad. A nice illustration of the difference between the top 2 lines in this table and the advantages of inlining.
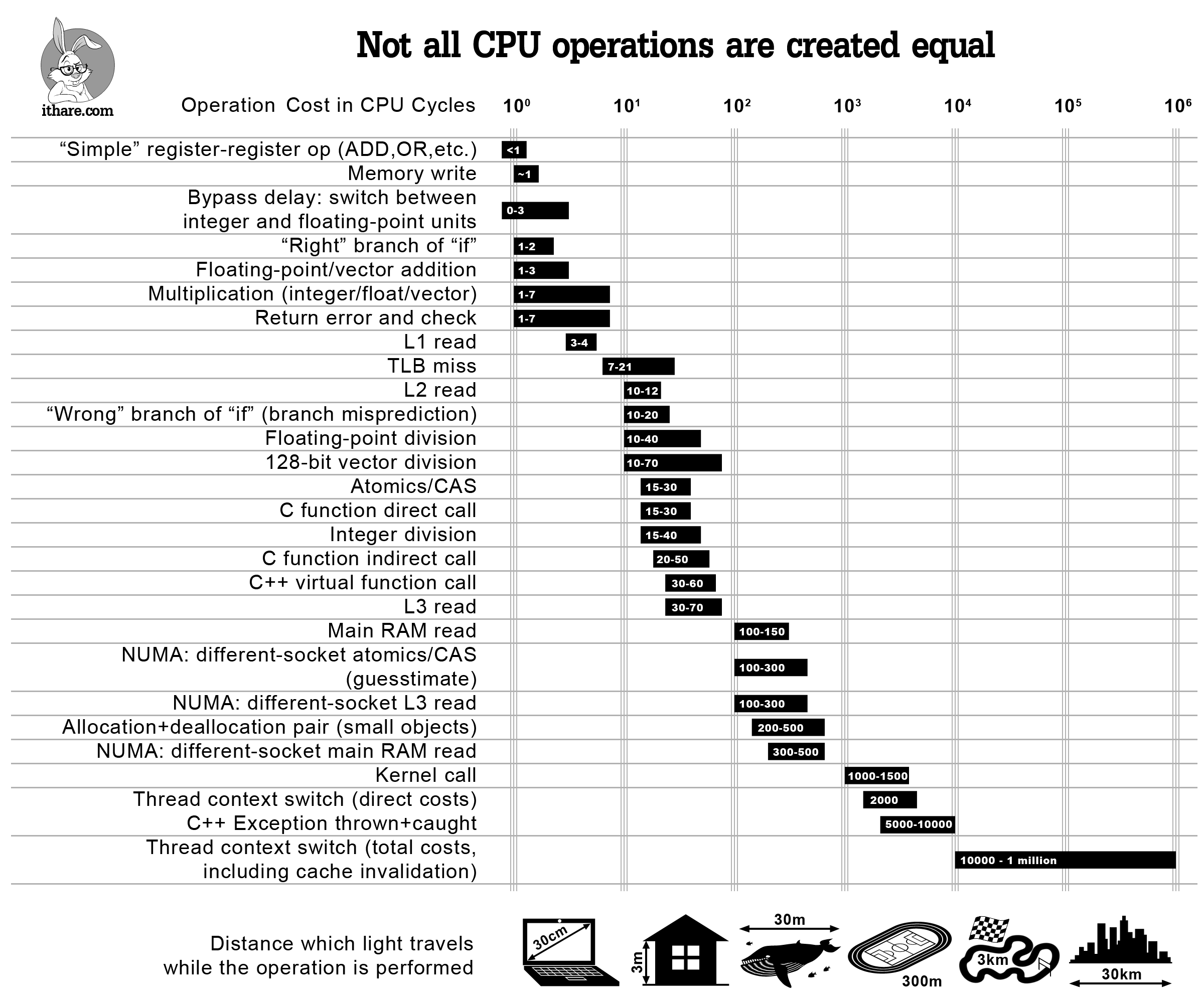
I got a remaining 1.15x speed up with minor optimizations in the ComputeScore function, like using a ternary for the initialization of moveScore or the change below which, while minor, compounded over 84 million calls.
Final lowest time measured for this deal was 1.22034, 1.5x faster than DevilSquirrel’s program on my machine (their machine was slightly faster).
They had also included stats for all deals. From their repo:
Game has 2000 total deals
Fastest deal is #1479 taking about 0.2s
Slowest deal is #1879 taking about 3.9s
Took 1704s (28m 24s) to solve all 2000 deals
Average solve time is about 0.85s
Lowest score is 80 in deal #1031
Highest score is 126 in deal #969
I stole the shuffling code and checked the stats for my version:
All in game deals solved (2000)
Total time: 1182.47s (19m 42s)
Average time: 0.591234
Max time: 2.64831s for deal: 1879
Min time: 0.145481s for deal: 1479
Highest Score: 126 for deal: 969
Lowest Score: 80 for deal: 1031
1.43x faster on average. As previously mentioned, the high-level approach ended up being the same. From what I understand they pre-allocate the cache and queue which is the most important for that part of the program. They store all moves made from the beginning and encode moves for a running stack in an int. There really isn’t much to this problem beyond the algorithm so the difference probably lies in the details, which I didn’t analyze in-depth. Being unfamiliar with Beef I’m not sure I’d be able to spot them anyway.
Main takeaways
That was a fun little project.
From a strictly technical standpoint, I didn’t learn much as I already knew how to solve this problem. The little optimization I did was applying theoretical knowledge. (e.g. memory is slow, computations are fast). For a real-world example, I liked this talk.
The most interesting part for me was to notice how easily I fell into a few mental traps.
Once you establish an abstraction to solve a problem, it’s hard to even conceive of alternatives.
Chris Zimmerman - The Rules of Programming
Simply reading “Dynamic Programming” in the context of this problem had me going down what I’d call a solution-first approach. I didn’t step back to consider what the actual problem was and what needed to be solved. It wasn’t much of a detour and in a way, it was a nice reminder of a few algorithmic concepts I don’t practice daily. But still, I should be more mindful.
Resist the temptation to keep optimizing. It’s easy to get caught up in the joy of tangible success and chase more performance wins you don’t need. Chris Zimmerman - The Rules of Programming
This one is more of a cautionary tail. This was mainly a “for fun” project and that was my main goal with it. I did notice this trend though, and again I’ll need to stay aware of it.
It looks like the main takeaway is I that should read The Rules of Programming again! It’s been a bit over a year since I read it, but I was still an aspiring programmer then. I’m sure I’ll get something very different out of it now that programming has been my job for almost a year.
I’d also forgotten how enjoyable and useful writing could be. Let’s hope I don’t have to rediscover that too frequently.